
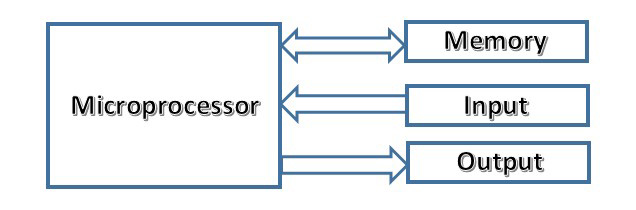
What Needs to be Done on a Process Schedule?
Process scheduling is a crucial aspect of operating system management, as it determines the order in which processes are executed by the CPU. The primary goals of process scheduling include efficient utilization of CPU time, fairness in resource allocation, and responsiveness to user requests. Here’s a breakdown of what needs to be done during a process schedule:

1. Selection of Next Process:
1.1 Ready Queue: The ready queue is a dynamic list that keeps track of all processes currently in the “ready” state, meaning they are prepared to execute and are waiting for CPU time. It serves as a pool of candidates eligible for execution.
The ready queue helps the scheduler efficiently choose the next process without wasting time evaluating processes that are not ready for execution.
1.2 Scheduling Algorithm: Various scheduling algorithms determine the order in which processes are selected from the ready queue for execution. Common algorithms include:
- First-Come-First-Serve (FCFS): Executes processes in the order they arrive in the ready queue.
- Shortest Job Next (SJN): Selects the process with the smallest total remaining processing time.
- Round Robin: Allocates a fixed time slice (quantum) to each process in turn, cycling through the ready queue.
- Priority Scheduling: Assigns priorities to processes, and the one with the highest priority is selected next.
2. Dispatcher Operation:
2.1 Context Switching: Context switching involves saving the current state (context) of the running process to the process control block (PCB). This includes register values, program counter, and other relevant information.
The saved context allows the operating system to later resume the execution of the process from where it was interrupted.
2.2 Load Context: Loading the context of the selected process from its PCB into the CPU involves restoring the saved values for registers, the program counter, and other necessary information.
This operation enables the operating system to continue the execution of the selected process seamlessly.
3. Synchronization:
3.1 Critical Sections: Critical sections are parts of code that access shared resources, and only one process can execute within a critical section at any given time. This prevents data corruption and ensures proper coordination.
The implementation of locks or other synchronization mechanisms helps enforce exclusive access to critical sections.
3.2 Mutexes and Semaphores: Mutexes and semaphores are synchronization primitives used to coordinate access to shared resources.
Mutexes allow only one process at a time to access a shared resource, while semaphores can control access based on a defined count, allowing a limited number of processes to enter a critical section simultaneously.
4. Process State Management:
4.1 State Transitions: Processes transition through various states during their lifecycle, including “ready,” “running,” “waiting,” and “terminated.”
The scheduler updates the state of processes as they move through these stages, ensuring accurate tracking of their progress.
4.2 Process Suspension and Resumption: Processes may need to be temporarily suspended and later resumed, such as when waiting for I/O operations to complete.
Suspension involves saving the process state, and resumption involves restoring the saved state to allow the process to continue execution.
5. Priority Adjustment:
5.1 Dynamic Priority Adjustment: Adjusting process priorities dynamically helps optimize system performance. Priorities may be based on factors like CPU burst time, resource requirements, or other characteristics.
The scheduler may elevate or lower a process’s priority dynamically to ensure efficient resource utilization and responsiveness.
5.2 Aging: Aging mechanisms prevent process starvation by gradually increasing the priority of processes that have been waiting for an extended period. This ensures that lower-priority processes eventually get a chance to execute, maintaining fairness in resource allocation.
6. Interrupt Handling:
6.1 Interrupt Service Routine (ISR): Interrupts are signals generated by hardware or software events that require immediate attention. The ISR is a specialized routine that handles these interrupts promptly.
The ISR saves the current context, processes the interrupt, and then restores the context to resume the interrupted process or initiate other necessary actions.
6.2 Interrupt Context Switching: If an interrupt occurs during process scheduling, the system must handle it smoothly. This involves transitioning from the currently running process to the interrupt handler while maintaining the integrity of both processes.
Proper interrupt context switching ensures that the system responds effectively to external events without causing errors or delays.
7. Resource Allocation:
7.1 Memory Management: Coordinate with the memory management subsystem to allocate and deallocate memory for processes as needed. This involves assigning memory blocks to processes, tracking available memory, and releasing memory when processes terminate.
Efficient memory management contributes to overall system stability and performance.
7.2 I/O Management: Manage I/O operations efficiently by coordinating with the I/O subsystem. This includes scheduling processes waiting for I/O resources, handling completion of I/O operations, and notifying processes when their requested I/O tasks are finished.
Effective I/O management ensures that processes can interact with peripheral devices and external resources without unnecessary delays.
8. Deadline Handling:
8.1 Deadline Enforcement: In real-time systems, where meeting deadlines is critical, processes are assigned specific deadlines for completion. The scheduler must enforce these deadlines to ensure that real-time tasks are executed within specified time constraints.
Monitoring and enforcing deadlines are crucial for applications with stringent timing requirements.
8.2 Missed Deadline Handling: Implement mechanisms to handle situations where a process fails to meet its deadline. This may involve logging the occurrence, triggering corrective actions, or notifying the system about the missed deadline.
Effective handling of missed deadlines helps maintain the reliability and predictability of real-time systems.
9. Load Balancing:
9.1 Balancing Workload: Distribute processes evenly across multiple CPUs or cores to optimize resource utilization. Load balancing aims to prevent certain processors from being overloaded while others remain underutilized.
Techniques such as process migration and dynamic workload distribution contribute to a more balanced system.
9.2 Migration: Process migration involves moving a process from one processor to another. This can be done to balance the workload across processors, reduce contention for resources, and enhance overall system performance.
Dynamic migration ensures that processes are placed on processors where they can execute efficiently.
10. User Interface Interaction:
10.1 User Interface Responsiveness: Prioritize processes that handle user interfaces to maintain system responsiveness and provide a seamless user experience. Responsive UI processes contribute to a positive user perception of the system’s performance.
This involves adjusting the scheduling algorithm to give preference to processes associated with user interactions.
10.2 Foreground and Background Processes: Distinguish between foreground and background processes and adjust their priorities accordingly. Foreground processes, often related to user interactions, may be given higher priority to ensure a smooth user experience.
Background processes, performing tasks with lower immediate user impact, may have lower priority to prevent them from affecting the responsiveness of foreground processes.
In conclusion, efficient process scheduling is vital for maintaining system performance, responsiveness, and overall stability in a multitasking environment. The specific implementation details may vary based on the operating system and its design.

is an experienced educator and academic currently serving as a Lecturer at Nurul Amin Degree College. With a career dedicated to student development and institutional excellence, he brings a wealth of classroom expertise and pedagogical knowledge to his current role. Before joining the faculty at Nurul Amin Degree College, he served as an Assistant Teacher at Zinzira PM Pilot School and College.







{kind=link}